Psycopg migrated to Bazaar
Last week we moved psycopg from Subversion to Bazaar. I did the migration using Gustavo Niemeyer's svn2bzr tool with a few tweaks to map the old Subversion committer IDs to the email address form conventionally used by Bazaar.
The tool does a good job of following tree copies and create related Bazaar branches. It doesn't have any special handling for stuff in the tags/ directory (it produces new branches, as it does for other tree copies). To get real Bazaar tags, I wrote a simple post-processing script to calculate the heads of all the branches in a tags/ directory and set them as tags in another branch (provided those revisions occur in its ancestry). This worked pretty well except for a few revisions synthesised by a previous cvs2svn migration. As these tags were from pretty old psycopg 1 releases I don't know how much it matters.
Psycopg2 2.0.7 Released
Yesterday Federico released version 2.0.7 of psycopg2 (a Python database adapter for PostgreSQL). I made a fair number of the changes in this release to make it more usable for some of Canonical's applications. The new release should work with the development version of Storm, and shouldn't be too difficult to get everything working with other frameworks.
Some of the improvements include:
- Better selection of exceptions based on the SQLSTATE result field. This causes a number of errors that were reported as ProgrammingError to use a more appropriate exception (e.g. DataError, OperationalError, InternalError). This was the change that broke Storm's test suite as it was checking for ProgrammingError on some queries that were clearly not programming errors.
- Proper error reporting for commit() and rollback(). These methods now use the same error reporting code paths as execute(), so an integrity error on commit() will now raise IntegrityError rather than OperationalError.
- The compile-time switch that controls whether the display_size member of Cursor.description is calculated is now turned off by default. The code was quite expensive and the field is of limited use (and not provided by a number of other database adapters).
- New QueryCanceledError and TransactionRollbackError exceptions. The first is useful for handling queries that are canceled by statement_timeout. The second provides a convenient way to catch serialisation failures and deadlocks: errors that indicate the transaction should be retried.
- Fixes for a few memory leaks and GIL misuses. One of the leaks was in the notice processing code that could be particularly problematic for long-running daemon processes.
- Better test coverage and a driver script to run the entire test suite in one go. The tests should all pass too, provided your database cluster uses unicode (there was a report just before the release of one test failing for a LATIN1 cluster).
If you're using previous versions of psycopg2, I'd highly recommend upgrading to this release.
Honey Bock Results
Since bottling the honey bock last month, I've tried a bottle last week and this week. While it is a very nice beer, the honey flavour is not very noticeable. That said, the second bottle I tried had a slightly stronger honey flavour than the first so it might just need to mature for another month or so.
If I was to do this beer again, it would make sense to use a stronger flavoured honey or just use more honey. Then again, perhaps it isn't worth trying honey flavoured dark beers.
Using email addresses as OpenID identities (almost)
On the OpenID specs mailing list, there was another discussion about using email addresses as OpenID identifiers. So far it has mostly covered existing ground, but there was one comment that interested me: a report that you can log in to many OpenID RPs by entering a Yahoo email address.
Now there certainly isn't any Yahoo-specific code in the standard OpenID libraries, so you might wonder what is going on here. We can get some idea by using the python-openid library:
Looms Rock
While doing a bit of work on Storm, I decided to try out the loom plugin for Bazaar. The loom plugin is designed to help maintain a stack of changes to a base branch (similar to quilt). Some use cases where this sort of tool are useful include:
- Maintaining a long-running diff to a base branch. Distribution packaging is one such example.
- While developing a new feature, the underlying code may require some refactoring. A loom could be used to keep the refactoring separate from the feature work so that it can be merged ahead of the feature.
- For complex features, code reviewers often prefer to changes to be broken down into a sequence of simpler changes. A loom can help maintain the stack of changes in a coherent fashion.
A loom branch helps to manage these different threads in a coherent manner. Each thread in the loom contains all the changes from the threads below it, so the revision graph ends up looking something like this:
bzr-dbus hacking
When working on my bzr-avahi plugin, Robert asked me about how it should fit in with his bzr-dbus plugin. The two plugins offer complementary features, and could share a fair bit of infrastructure code. Furthermore, by not cooperating, there is a risk that the two plugins could break when both installed together.
Given the dependencies of the two packages, it made more sense to put common infrastructure in bzr-dbus and have bzr-avahi depend on it. That said, bzr-dbus is a bit more difficult to install than bzr-avahi, since it requires installation of a D-Bus service activation file. After looking at the code, it seemed that there was room to simplify how bzr-dbus worked and improve its reliability at the same time.
Running Valgrind on Python Extensions
As most developers know, Valgrind is an invaluable tool for finding memory leaks. However, when debugging Python programs the pymalloc allocator gets in the way.
There is a Valgrind suppression file distributed with Python that gets rid of most of the false positives, but does not give particularly good diagnostics for memory allocated through pymalloc. To properly analyse leaks, you often need to recompile Python with pymalloc.
As I don't like having to recompile Python I took a look at Valgrind's client API, which provides a way for a program to detect whether it is running under Valgrind. Using the client API I was able to put together a patch that automatically disables pymalloc when appropriate. It can be found attached to bug 2422 in the Python bug tracker.
Honey Bock
Yesterday I bottled the honey bock that has been brewing over the last week. This one was made with the following ingredients:
- A Black Rock Bock beer kit.
- 1kg of honey
- 500g of Dextrose
- Caster sugar for carbonation
The only difference from the standard procedure was replacing part of the brewing sugar with honey. Before being added, the honey needs to be pasteurised, which involves heating it up to 80°C and keeping it at that temperature for half an hour or so. This kills off any any wild yeasts or other undesirables that might spoil the brew.
Two‐Phase Commit in Python's DB‐API
Marc uploaded a new revision of the Python DB-API 2.0 Specification yesterday that documents the new two phase commit extension that I helped develop on the db-sig mailing list.
My interest in this started from the desire to support two phase commit in Storm – without that feature there are far fewer occasions where its ability to talk to multiple databases can be put to use. As I was doing some work on psycopg2 for Launchpad, I initially put together a PostgreSQL specific patch, which was (rightly) rejected by Federico.
Zeroconf Branch Sharing with Bazaar
![]()
When collaborating with someone at one of these sprints the usual way to let others look at my work would be to commit the changes so that they could be pulled or merged by others. With legacy version control systems like CVS or Subversion, this would generally result in me uploading all my changes to a server in another country only for them to be downloaded back to the sprint location by others.
Client Side OpenID
The following article discusses ideas that I wouldn't even class as vapourware, as I am not proposing to implement them myself. That said, the ideas should still be implementable if anyone is interested.
One well known security weakness in OpenID is its weakness to phishing attacks. An OpenID authentication request is initiated by the user entering their identifier into the Relying Party, which then hands control to the user's OpenID Provider through an HTTP redirect or form post. A malicious RP may instead forward the user to a site that looks like the user's OP and record any information they enter. As the user provided their identifier, the RP knows exactly what site to forge.
Re: Python factory-like type instances
Nicolas:
Your metaclass example is a good example of when not to use metaclasses.
I wouldn't be surprised if it is executed slightly different to how you
expect. Let's look at how Foo is evaluated, starting with what's
written:
class Foo:
__metaclass__ = FooMeta
This is equivalent to the following assignment:
Foo = FooMeta('Foo', (), {...})
As FooMeta has an __new__() method, the attempt to instantiate
FooMeta will result in it being called. As the return value of
__new__() is not a FooMeta instance, there is no attempt to call
FooMeta.__init__(). So we could further simplify the code to:
Allocated Seating at Greater Union
On the weekend, I had my first encounter with allocated seating at the Greater Union Innaloo cinemas.
As usual, we'd bought tickets separately. It wasn't until going in to the actual cinema that a staff member said that we were expected to sit in seats scattered around the cinema (one of which was on the very edge).
As the cinema wasn't completely full, we did the only sensible thing: ignore the allocations and pick some seats next to each other. Looking around the cinema, it looked like a number of other people were ignoring the allocations (the seat I'd been allocated was taken by someone else in a group of about 5 people).
urlparse considered harmful
Over the weekend, I spent a number of hours tracking down a bug caused
by the cache in the Python urlparse
module. The problem
has already been reported as Python bug
1313119, but has not been fixed
yet.
First a bit of background. The urlparse module does what you'd expect
and parses a URL into its components:
>>> from urlparse import urlparse
>>> urlparse('http://www.gnome.org/')
('http', 'www.gnome.org', '/', '', '', '')
As well as accepting byte strings (which you'd be using at the HTTP protocol level), it also accepts Unicode strings (which you'd be using at the HTML or XML content level):
OpenID 2.0 Specification Approved
It looks like the OpenID Authentication 2.0 specification has finally been released, along with OpenID Attribute Exchange 1.0. While there are some questionable features in the new specification (namely XRIs), it seems like a worthwhile improvement over the previous specification. It will be interesting to see how quickly the new specification gains adoption.
While this is certainly an important milestone, there are still areas for improvement.
Best Practices For Managing Trust Relationships With OPs
States in Version Control Systems
Elijah has been writing an interesting series of articles comparing different version control systems. While the previous articles have been very informative, I think the latest one was a bit muddled. What follows is an expanded version of my comment on that article.
Elijah starts by making an analogy between text editors and version control systems, which I think is quite a useful analogy. When working with a text editor, there is a base version of the file on disk, and the version you are currently working on which will become the next saved version.
Inkscape Migrated to Launchpad
Yesterday I performed the migration of Inkscape's bugs from SourceForge.net to Launchpad. This was a full import of all their historic bug data – about 6900 bugs.
As the import only had access to the SF user names for bug reporters,
commenters and assignees, it was not possible to link them up to
existing Launchpad users in most cases. This means that duplicate person
objects have been created with email addresses like
$USERNAME@users.sourceforge.net.
OpenID Attribute Exchange
In my previous article on OpenID 2.0, I mentioned the new Attribute Exchange extension. To me this is one of the more interesting benefits of moving to OpenID 2.0, so it deserves a more in depth look.
As mentioned previously, the extension is a way of transferring information about the user between the OpenID provider and relying party.
Why use Attribute Exchange instead of FOAF or Microformats?
Weird GNOME Power Manager error message
Since upgrading to Ubuntu Gutsy I've occasionally been seeing the following notification from GNOME Power Manager:
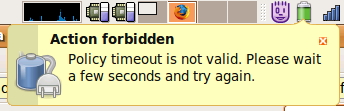
I'd usually trigger this error by unplugging the AC adapter and then picking suspend from GPM's left click menu.
My first thought on seeing this was "What's a policy timeout, and why
is it not valid?" followed by "I don't remember setting a policy
timeout". Looking at bug
492132 I found a
pointer to the policy_suppression_timeout gconf value, whose
description gives a bit more information.
Identifier Reuse in OpenID 2.0
One of the issues that the OpenID 1.1 specification did not cover is the fact that an identity URL may not remain the property of a user over time. For large OpenID providers there are two cases they may run into:
- A user with a popular user name stops using the service, and they want to make that name available to new users.
- A user changes their user name. This may be followed by someone taking over the old name.
In both cases, RPs would like some way to tell the difference between two different users who present the same ID at different points in time.
Beer Pouring Machine
One of the novelties in the airport lounge at Narita was a beer pouring machine. It manages to consistently pour a good glass of beer every time. You start by placing the glass in the machine:

When you press the start button, it tilts the glass and pours the beer down the side of the glass:

After filling the glass the machine tilts the glass upright again and some extra foam comes out of the second nozzle:
On the way to Boston
I am at Narita Airport at the moment, on the way to Boston for some of the meetings being held during UDS. It'll be good to catch up with everyone again.
Hopefully this trip won't be as eventful as the previous one to Florida :)
OpenID 2.0
Most people have probably seen or used OpenID. If you have used it, then it has most likely that it was with the 1.x protocol. Now that OpenID 2.0 is close to release (apparently they really mean it this time ...), it is worth looking at the new features it enables. A few that have stood out to me include:
- proper extension support
- support for larger requests/responses
- directed identity
- attribute exchange extension
- support for a new naming monopoly
I'll now discuss each of these in a bit more detail
Back from Dunedin
Last week I was in sunny Dunedin for a Launchpad/Bazaar integration sprint with Tim and Jonathan. Some of the smaller issues we addressed should make their way to users in the next Launchpad release (these were mainly fixes to confusing error messages on bazaar.launchpad.net). Some of the others will probably only become available a release or two further on (mostly related to improving development workflow for branches hosted on Launchpad).
My previous trip to New Zealand had also been to Dunedin (for last year's linux.conf.au). Since then they'd replaced all the coins for denominations less than NZ$1. Other than being less familiar to Australians, the smaller coins seem like a good idea. They don't seem to have taken Australia's lead in making the $2 coin smaller than the $1 coin though.
Google's Australian Election Tools
It is probably old news to some, but Google have put up an information page on the upcoming Australian Federal Election.
The most useful tool is the Google Maps overlay that provides information about the different electorates. At the moment it only has information about the sitting members, their margin and links to relevant news articles. Presumably more information will become available once the election actually gets called.
Presumably they are planning on offering similar tools for next year's US elections and this is a beta. So even if you aren't interested in Australian politics, it might be worth a peak to see what is provided.