Merging In Bazaar
This posting follows on from my previous postings about Bazaar, but is a bit more advanced. In most cases you don’t need to worry about this, since the tools should just work. However if problems occur (or if you’re just curious about how things work), it can be useful to know a bit about what’s going on inside.
Changesets vs. Tree Snapshots
A lot of the tutorials for Arch list “changeset orientation” as one of its benefits over other systems such as Subversion, which were said to be based on “tree snapshots”. At first this puzzled me, since from my mathematical background the relationship between these two concepts seemed the same as the relationship between integrals and derivatives:
- A changeset is just the difference between two tree snapshots.
- The state of a tree at a particular point in just the result of taking the initial tree state (which might be an empty tree), and applying all changesets on the line of development made before that point.
The distinction isn’t clear cut in the existing tools either – Subversion uses changesets to store the data in the repository while providing a “tree snapshot” style view, and Bazaar generates tree snapshots in its revision library to increase performance of some operations.
So the distinction people talk about isn’t a simple matter of the repository storage format. Instead the difference is in the metadata stored along with the changes that describes the ancestry of the code.
Changesets and Branching
In the simple case of a single branch, you end up with a simple series
of changesets. The tree for each revision is constructed by taking the
last revision’s tree and applying the relevant changeset.
Alternatively, you can say that the tree for patch-3 contains the
changesets base-0, patch-1, patch-2 and patch-3.

Branching fits into this model pretty well. As with other systems, a
particular revision can have multiple children. In the diagram below,
the trees for both patch-2 from the original branch and patch-1 from
the new branch “contain” base-0 and patch-1 from the original
branch. Any apparent asymmetry is just in the naming and storage
locations – both revisions are branches are just patches against the
same parent revision.
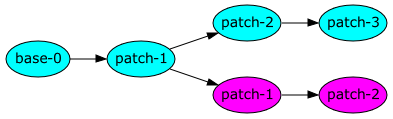
So far, there’s no rocket science. Nothing that Subversion doesn’t
represent. Pretty much every version control system under the sun tracks
this kind of linear revision ancestry (as can be seen using svn log or
similar). The differences really only become apparent when merges are
taken into consideration.
Merges
Just as a particular revision can have multiple child revisions (a.k.a. branching), a tree can have multiple parent revisions when merges occur. When you merge two revisions, the result should contain all the changes that exist in the parent revisions.
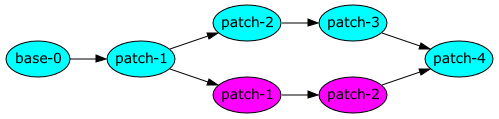
In the above diagram, we want to merge the changes made on the second branch back into the original one. The usual way to merge changes goes something like this:
- Identify the most recent common ancestor of the two revisions.
- Take the difference between one of the revisions to merge and apply those changes to the other revision.
If the changes on the two branches are to different parts of the tree, this process can be done without any extra user intervention. If the two branches touch the same bits of code, the conflicts will have to be resolved manually.
It is important to pick the most recent common ancestor, otherwise the real changes in the two branches will get mixed in with changes common to the two branches, which can result in spurious merge conflicts.
In this particular case, it is obvious which common ancestor to use:
patch-1 from the original branch. In Arch, the result of the merge is
represented as a changeset on the original branch that contains the
changes found on the second branch. In addition to the changes, it adds
some metadata (known as patch logs) that records that patch-1 and
patch-2 from the second branch have been merged in. This becomes
important when performing future merges between the two branches.
Repeated Merges
While it was possible to pick the correct merge ancestor in the previous
example using just the linear revision ancestry of the two branches,
that isn’t true for subsequent merges between the two branches.
Consider the following merge that results in patch-6 on the original
branch:

Here the best merge ancestor to use is patch-2 on the second branch.
However, without the record of the previous merge, the same ancestor as
the previous merge would be chosen (which is what CVS will do by default
with repeated merges).
While the above ancestor could be selected by just recording when you last merged with a particular branch, that is not sufficient when there are merges between more than two branches.
More Than Two Branches
Below is a fairly simple example involving three branches, where some changes have been merged from the third branch (yellow) into the original branch (cyan) and the second branch (magenta). Finally, there is a merge between the magenta and cyan branches.
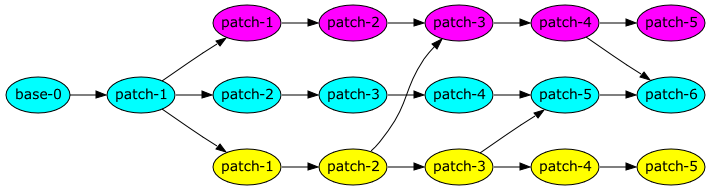
For this last merge, there are a number of possible merge ancestors. If
we ignore the yellow branch, the latest common ancestor is the initial
branch point. This would result in merging the changes in patch-1,
patch-2, patch-3 and patch-4 from the second branch into the
patch-5 tree on the original branch. However, this is likely to result
in a number of conflicts, since both branches contain changes merged
from the yellow branch, which are going to overlap.
The better common ancestor ancestor to choose in this case is patch-2
on the yellow branch, which avoids the common changes.
Bazaar’s merge command will handle this kind of merge ancestry just
fine (something that isn’t true for of the older tla star-merge
algorithm).
Conclusion
This article doesn’t cover all aspects of branching and merging with Bazaar. One aspect I have completely ignored is the concept of “cherry picking”. This refers to applying a particular change to a tree, without the other changesets that exist on that branch. Cherry picking is mostly orthogonal to standard merging — in fact, one of the complications in merge ancestor selection is that it needs to ignore cherry picked patches.
Network effects also come into play here — if you make your code available as an Arch branch, then Bazaar is more useful to others since they can branch and merge with your archive (and the reverse holds too). The Ubuntu Arch imports certainly help here, but to get the full advantage of the advanced merge capabilities both sides need to be tracking history.
Comments:
Alexander Larsson -
There are some problems with the form of three way merges you describe. Take a look at this thread from the monotone list:
http://lists.gnu.org/archive/html/monotone-devel/2005-05/msg00000.html
Apparently there can be cases where its impossible to pick an ancestor so that the three-way merge doesn’t silently corrupt code.
James Henstridge -
As Arch uses persistent identifiers for files, it would be able to detect the problems mentioned in that mailing list post, and treat them as conflicts.
Yes, this may result in more conflicts than a “perfect merge”, but I don’t think it would lead to the silent corruption that you mention (i.e. some of the problems only occur when you move to non-persistent IDs).
Bazaar definitely has some warts, but it is useful for real work right now, and will offer a smooth upgrade path to bazaar-ng (which gets rid of some warts that are required for compatibility with the Arch protocol).
H Duerer -
I thought the real question was not whether to use Arch or Subversion but rather Arch or Darcs (or … ).
As many before me I have found Darcs easier to use and have not yet come across some newbie-suitable explanation why arch would be preferable. Same explanations in that direction would surely be appreciated.